Alex’s Adventures in Numberland (68 page)
Read Alex’s Adventures in Numberland Online
Authors: Alex Bellos

When I first drew this out I felt relief, as it really looked like my baguette experiment was producing a bell curve. My facts appeared to be fitting the theory. A triumph for applied science! But when I looked closer, the graph wasn’t really like the bell curve at all. Yes, the weights were clustered around a mean, but the curve was clearly not symmetrical. The left side of the curve was not as steep as the right side. It was as if there was an invisible magnet stretching the curve a little to the left.
I could therefore conclude one of two things. Either the weights of Greggs’ baguettes were not normally distributed, or they were normally distributed but some bias had crept in to my experimentation process. I had an idea of what the bias might be. I had been storing the uneaten baguettes in my kitchen, and I decided to weigh one that was a few days old. To my surprise it was only 321g – significantly lower than the lowest weight I had measured. It dawned on me then that baguette weight was not fixed because bread gets lighter as it dries out. I bought another loaf and discovered that a baguette loses about 15g between 8 a.m. and noon.
It was now clear that my experiment was flawed. I had not taken into account the hour of the day when I took my measurements. It was almost certain that this variation was providing a bias to the distribution of weights. Most of the time I was the first person in the shop, and weighed my loaf at about 8.10 a.m., but sometimes I got up late. This random variable was not normally distributed since the mean would have been between 8 and 9 a.m., but there was no tail before 8 a.m. since the shop was closed. The tail on the other side went all the way to lunchtime.
Then something else occurred to me. What about the ambient temperature? I had started my experiment at the beginning of spring. It had ended at the beginning of summer, when the weather was significantly hotter. I looked at the figures and saw that my baguette weights were lighter on the whole towards the end of the project. The summer heat, I assumed, was drying them out faster. Again, this variation could have had the effect of stretching the curve leftwards.
My experiment may have shown that baguette weights approximated a slightly distorted bell curve, yet what I had really learned was that measurement is never so simple. The normal distribution is a theoretical ideal, and one cannot assume that all results will conform to it. I wondered about Henri Poincaré. When he measured his bread did he eliminate bias due to the Parisian weather, or the time of day of his measurements? Perhaps he had not demonstrated that he was being sold a 950g loaf instead of a 1kg loaf at all, but had instead proved that from baking to measuring, a 1kg loaf reduces in weight by 50g.
The history of the bell curve, in fact, is a wonderful parable about the curious kinship between pure and applied scientists. Poincaré once received a letter from the French physicist Gabriel Lippmann, who brilliantly summed up why the normal distribution was so widely exalted: ‘Everybody believes in the [bell curve]: the experimenters because they think it can be proved by mathematics; and the mathematicians because they believe it has been established by observation.’ In science, as in so many other spheres, we often choose to see what serves our interests.
Francis Galton devoted himself to science and exploration in the way that only a man in possession of a large fortune can do. His early adulthood was spent leading expeditions to barely known parts of Africa, which brought him considerable fame. A masterful dexterity with scientific instruments enabled him, on one occasion, to measure the figure of a particularly buxom Hottentot by standing at a distance and using his sextant. This incident, it seems, was indicative of a desire to keep women at arm’s length. When a tribal chief later presented him with a young woman smeared in butter and red ochre in preparation for sex – Galton declined the offer, concerned she would smudge his white linen suit.
Eugenics was Galton’s most infamous scientific legacy, yet it was not his most enduring innovation. He was the first person to use questionnaires as a method of psychological testing. He devised a classification system for fingerprints, still in use today, which led to their adoption as a tool in police investigations. And he thought up a way of illustrating the weather, which when it appeared in
The Times
in 1875 was the first public weather map to be published.
That same year, Galton decided to recruit some of his friends for an experiment with sweet peas. He distributed seeds among seven of them, asking them to plant the seeds and return the offspring. Galton measured the baby seeds and compared their diameters to those of their parents. He noticed a phenomenon that initially seems counter-intuitive: the large seeds tended to produce smaller offspring, and the small seeds tended to produce larger offspring. A decade later he analysed data from his anthropometric laboratory and recognized the same pattern with human heights. After measuring 205 pairs of parents and their 928 adult children, he saw that exceptionally tall parents had kids who were generally shorter than they were, while exceptionally short parents had children who were generally taller than their parents.
After reflecting upon this, we can understand why it must be the case. If very tall parents always produced even taller children, and if very short parents always produced even shorter ones, we would by now have turned into a race of giants and midgets. Yet this hasn’t happened. Human populations may be getting taller as a whole – due to better nutrition and public health – but the distribution of heights within the population is still contained.
Galton called this phenomenon ‘regression towards mediocrity in hereditary stature’. The concept is now more generally known as
regression to the mean
. In a mathematical context, regression to the mean is the statement that an extreme event is likely to be followed by a less extreme event. For example, when I measured a Greggs baguette and got 380g, a very low weight, it was very likely that the next baguette would weigh more than 380g. Likewise, after finding a 420g baguette, it was very likely that the following baguette would weigh less than 420g. The quincunx gives us a visual representation of the mechanics of regression. If a ball is put in at the top and then falls to the furthest position on the left, then the next ball dropped will probably land closer t the middle position – because most of the balls dropped will land in the middle positions.
Variation in human height through generations, however, follows a different pattern from variation in baguette weight through the week or variation in where a quincunx ball will land. We know from experience that families with above-average-sized parents tend to have above-average-sized kids. We also know that the shortest guy in the class probably comes from a family with adults of correspondingly diminutive stature. In other words, the height of a child is not totally random in relation to the height of his parents. On the other hand, the weight of a baguette on a Tuesday probably
is
random in relation to the weight of a baguette on a Monday. The position of one ball in a quincunx is (for all practical purposes) random in relation to any other ball dropped.
In order to understand the strength of association between parental height and child height, Galton came up with another idea. He plotted a graph with parental height along one axis and child height along the other, and then drew a straight line through the points that best fitted their spread. (Each set of parents was represented by the height midway between mother and father – which he called the ‘mid-parent’). The line had a gradient of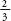 . In other words for every inch taller than the average that the mid-parent was, the child would only beof an inch taller than the average. For every inch shorter than the average the mid-parent was, the child would only beof an inch shorter than the average. Galton called the gradient of the line the
. In other words for every inch taller than the average that the mid-parent was, the child would only beof an inch taller than the average. For every inch shorter than the average the mid-parent was, the child would only beof an inch shorter than the average. Galton called the gradient of the line the
coefficient of correlation
. The coefficient is a number that determines how strongly two sets of variables are related. Correlation was more fully developed by Galton’s protégé Karl Pearson, who in 1911 set up the world’s first university statistics department, at University College London.
Regression and correlation were major breakthroughs in scientific thought. For Isaac Newton and his peers, the universe obeyed deterministic laws of cause and effect. Everything that happened had a reason. Yet not all science is so reductive. In biology, for example, certain outcomes – such as the occurrence of lung cancer – can have multiple causes that mix together in a complicated way. Correlation provided a way to analyse the fuzzy relationships between linked sets of data. For example, not everyone who smokes will develop lung cancer, but by looking at the incidence of smoking and the incidence of lung cancer mathematicians can work out your chances of getting cancer if you do smoke. Likewise, not every child from a big class in school will perform less well than a child from a small class, yet class sizes do have an impact on exam results. Statistical analysis opened up whole new areas of research – in subjects from medicine to sociology, from psychology to economics. It allowed us to make use of information without knowing exact causes. Galton’s original insights helped make statistics a respectable field: ‘Some people hate the very name of statistics, but I find them full of beauty and interest,’ he wrote. ‘Whenever they are not brutalized, but delicately handled by the higher methods, and are warily interpreted, their power of dealing with complicated phenomena is extraordinary.’
In 2002 the Nobel Prize in Economics was not won by an economist. It was won by the psychologist Daniel Kahneman, who had spent his career (much of it together with his colleague Amos Tversky) stdying the cognitive factors behind decision-making. Kahneman has said that understanding regression to the mean led to his most satisfying ‘Eureka moment’. It was in the mid 1960s and Kahneman was giving a lecture to Israeli air-force flight instructors. He was telling them that praise is more effective than punishment for making cadets learn. On finishing his speech, one of the most experienced instructors stood up and told Kahneman that he was mistaken. The man said: ‘On many occasions I have praised flight cadets for clean execution of some aerobatic manœuvre, and in general when they try it again, they do worse. On the other hand, I have often screamed at cadets for bad execution, and in general they do better the next time. So please don’t tell us that reinforcement works and punishment does not, because the opposite is the case.’ At that moment, Kahneman said, the penny dropped. The flight instructor’s opinion that punishment is more effective than reward was based on a lack of understanding of regression to the mean. If a cadet does an extremely bad manœuvre, then of course he will do better next time – irrespective of whether the instructor admonishes or praises him. Likewise, if he does an extremely good one, he will probably follow that with something less good. ‘Because we tend to reward others when they do well and punish them when they do badly, and because there is regression to the mean, it is part of the human condition that we are statistically punished for rewarding others and rewarded for punishing them,’ Kahneman said.