The Articulate Mammal (38 page)
Read The Articulate Mammal Online
Authors: Jean Aitchison

1 Comprehension and production are totally different.
2 Comprehension is production in reverse.
3 Comprehension is the same as production: that is, comprehenders reconstruct the message for themselves in the same way as they would construct it if they were speakers.
4 Comprehension and production are partially the same and partially different.
This range of options means that we must deal with comprehension and production separately. We shall begin with speech understanding, because this has been more intensively studied.
HEARING WHAT WE EXPECT TO HEAR
At the beginning of the twentieth century, psycholinguists assumed that the process of understanding speech was a simple one. The hearer was envisaged, metaphorically, as a secretary taking down a dictation. She mentally wrote down the sounds she heard one by one, then read off the words formed by them. Or, taking another metaphor, the hearer was envisaged as a detective solving a crime by matching fingerprints to known criminals. All the detective had to do was match a fingerprint found on the scene of the crime against one on his files, and see who it belonged to. Just as no two people’s fingerprints are the same, so each sound was regarded as having a unique acoustic pattern.
Unfortunately, this simple picture turns out to be wrong. A series of experiments conducted by phoneticians and psycholinguists disproved the ‘passive secretary’ or ‘fingerprints’ approach. There are a number of problems.
First of all, it is clear that hearers cannot ‘take down’ or ‘match’ sounds one by one. Apart from anything else, the speed of utterance makes this an impossible task. If we assume an average of four sounds per English word, and a speed of five words a second, we are expecting the ear and brain to cope with around twenty sounds a second. But humans cannot process this number of separate signals in that time – it is just too many (Liberman
et al.
1967).
A second reason why the ‘passive secretary’ or ‘fingerprint’ approach does not work is that there is no fixed acoustic representation of, say, a T, parallel to the fixed typewriter symbol T. The acoustic traces left by sounds are quite unlike the fingerprints left by criminals. In actual speech, each sound varies considerably depending on what comes before and after it. The T in TOP differs from the T in STOP or the T in BOTTLE. In addition, a sound varies from speaker to speaker to a quite surprising extent. So direct matching of each sound is impossible.
A third, related problem is that sounds are acoustically on a continuum: B gradually shades into D which in turn shades into G. There is no definite borderline between acoustically similar sounds, just as it is not always possible to distinguish between a flower vase and a mug, or a bush and a tree (Liberman
et al.
1967).
These findings indicate that there is no sure way in which a human can ‘fingerprint’ a sound or match it to a single mental symbol, because the acoustic patterns of sounds are not fixed and distinct. And even if they were, people would not have time to identify each one positively. The information extracted from the sound waves forms ‘no more than a rough guide to the
sense of the message, a kind of scaffolding upon which the listener constructs or reconstructs the sentences’ (Fry 1970: 31).
In interpreting speech sounds, hearers are like detectives who find that solving a crime is not a simple case of matching fingerprints to criminals. Instead, they find a situation where ‘a given type of clue might have been left by any of a number of criminals or where a given criminal might have left any of a number of different types of clue’ (Fodor
et al
. 1974: 301). What they are faced with is ‘more like the array of disparate data from which Sherlock Holmes deduces the identity of the criminal.’ In such cases, the detectives’ background information must come into play.
In other words, deciphering the sounds of speech is an
active
not a passive process. Hearers have to compute
actively
the possible phonetic message by using their background knowledge of the language. This is perhaps not so astonishing. We have plenty of other evidence for the active nature of this process. We all know how difficult it is to hear the exact sounds of a foreign word. This is because we are so busy imposing on it what we expect to hear, in terms of our own language habits, that we fail to notice certain novel features.
IDENTIFYING WORDS
Listeners try first of all to identify words. They are ‘constrained by the sounds of language, on the one hand, and by the desire to make sense of what they hear on the other’ (Bond 1999: xvii). Consequently, we can find out quite a lot by looking both at English word structure, and at mishearings or ‘slips of the ear’. English words contain some useful clues about their beginnings and endings. For example, T at the beginning of a word has a puff of breath (aspiration) after it, and –ING often comes at the end of a word. As a result, when someone mishears a word, it is typically a whole word: 85 per cent of mishearings involved single words in one study (Browman 1980). And this has been confirmed by later studies, as with RACING for RAISING in the sentence: ‘He’s in the turkey-raising businesss’, GRANDMA for GRAMMAR in the phrase ‘Grammar Workshop’, and CHAMELEON heard as COMEDIAN (Bond 1999).
As soon as a hearer comes across the beginning of a word, he or she starts making preliminary guesses as to what it might be. It would take far too long to check out each guess one by one, and numerous words are considered at the same time: ‘There is now considerable evidence that, during spoken-word recognition, listeners evaluate multiple lexical hypotheses in parallel’ (McQueen 2005: 230).
Exactly how this is done is disputed. One suggestion is that as soon as the beginning of a word is detected, the hearer immediately flashes up onto his or her mental screen a whole army of words with a similar beginning. The hearer hears maybe ‘HAVE YOU SEEN MY P …?’ At this point her mind conjures up a
whole list of words which start in a similar way, maybe ‘PACK, PAD, PADLOCK, PAN, PANDA, PANSY’. This idea is known as the ‘cohort’ model. Words beginning with the same sounds were envisaged as lining up like soldiers in a cohort, a division of the Roman army (Marslen-Wilson and Tyler 1980). The hearer then eliminates those that do not fit in with the sound or meaning of the rest of the sentence. But the cohort model, in its original form, did not allow for the fact that even if a hearer missed the first sound, it was still possible to make a plausible guess about the word being heard. If someone heard BLEASANT then the degree of overlap with PLEASANT, and the lack of any word BLEASANT, together with the context, allowed the hearer to make a good guess. So the model was amended to allow for more than just the initial sound, even though it was widely recognized that initial sounds, if heard properly, are very important for word identification.
But this widening of the information accessed meant that the revised cohort model was similar to another, more powerful type of framework, known as ‘spreading activation’ or ‘interactive activation’ models, which can be envisaged as working somewhat like electric circuitry, in which the current flows backwards and forwards, rushing between the initial sounds heard, and the words aroused. The sounds will activate multiple meanings, then the other meanings triggered will arouse further sounds. BLEASANT would eventually fade away, but PLEASANT might trigger, say, PHEASANT, PLEASURE, and others. Those which fitted in with other aspects of the sentence, the meaning and the syntax, would get more and more activated, and those which seemed unlikely would fade away. These network models, in which everything is (ultimately) connected to everything else, are sometimes referred to by the general label ‘connectionism’ (McClelland and Elman 1986).
Inevitably, controversy exists as to how such models work, and several variants have been proposed. A model that is currently being assessed is labelled ‘Shortlist’ (Norris 1994, 2005), which proposes that ‘a lexical lookup process … identifies all the words that correspond to sequences of phonemes in the input. So, for example, the input CATALOG would match the words CAT, CATTLE, A, LOG, and CATALOG.’ (Norris 2005: 336). Here, CATALOG would emerge as the winner, as shown in the following diagram.
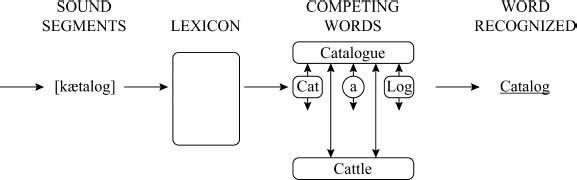
Hearers are not aware of these multiple word choices, just as they are unaware that when they hear an ambiguous word (such as BANK which could be a financial institution or the edge of a river) they mentally consider more than one meaning. This somewhat suprising discovery was made well over a quarter of a century ago, when psycholinguists were first seriously interested in ambiguity. They discovered that hearers consider multiple meanings, though often subconsciously. When subjects were asked to check for the presence of a given sound in a sentence (‘Press a button if you come to a word starting with B’), a procedure known as ‘phoneme monitoring’, an ambiguous word slowed them down even when they claimed not to have noticed the ambiguity (Foss 1970). For example, they responded more slowly to the B in a sentence such as:
THE SEAMEN STARTED TO DRILL BEFORE THEY WERE ORDERED TO DO SO.
(drill holes or take part in a life-boat drill?), than in:
THE SEAMEN STARTED TO MARCH BEFORE THEY WERE ORDERED TO DO SO.
Furthermore, even irrelevant meanings are apparently considered. In one now famous experiment (Swinney 1979), passages containing homonyms (words with more than one meaning) were read out to subjects. For example:
THE MAN FOUND SEVERAL SPIDERS, ROACHES AND OTHER BUGS IN THE CORNER OF THE ROOM.
Here BUGS clearly referred to insects, though in another context, BUGS could be electronic listening devices. Just after the ambiguous word, the experimenter flashed a sequence of letters up on to a screen, and asked if they formed a word or not (a so-called ‘lexical decision task’). He found that subjects responded fastest to words which were related to
either
meaning of the ambiguous word. They said ‘Yes’ faster to ANT and SPY than they did to SEW. And this was not just due to some accidental experimental effect, because other psycholinguists came to the same conclusion (e.g. Tanenhaus
et al.
1979; Seidenberg
et al.
1982; Kinoshita 1986).
More surprising still, perhaps, subjects reacted similarly even with a homonym such as ROSE which involves two different parts of speech, a noun (the flower) and a verb (past tense of RISE). They were played four sentences, which included the words:
THEY BOUGHT A ROSE.
THEY BOUGHT A SHIRT.
THEY ALL ROSE.
THEY ALL STOOD.
The subjects responded fastest to a lexical decision about the word FLOWER following
either
type of ROSE, both the noun and the verb (Seidenberg
et al.
1982).
This may be a ‘veiled controlled process’, in that it is neither automatic, nor consciously carried out. ‘Veiled controlled processes are opaque to consciousness, faster than conscious controlled processes, and they make fewer demands on limited processing resources’ (Tanenhaus
et al.
1985: 368).
Much more is going on than we consciously realize. Any human is like a powerful computer in that the limited amount of information appearing on his or her mental screen at any one time gives no indication of the multiple processes which have whizzed through in the computer’s inner workings. And these human processes are happening in parallel, rather than one after the other, and are more impressive even than those found in the world’s most powerful computers. Computers which can deal with the multiple computations routinely carried out by humans are still a future dream.
But exactly how much parallel processing is going on in humans? Verbs are a particular area of controversy. Do humans activate in parallel
all
structures that can occur with them? Let us consider this matter.
VERSATILE VERBS
‘They’ve a temper some of them – particularly verbs, they’re the proudest – adjectives you can do anything with, but not verbs.’ This comment by Humpty Dumpty to Alice in Lewis Carroll’s
Through the Looking Glass
reflects a feeling shared by many psycholinguists that verbs are more complicated than other parts of speech. They may provide the ‘key’ to the sentence by imposing a structure on it.
The effect of verbs has been a major issue for around half a century. Fodor
et al
. (1968) suggested that when someone hears a sentence, they pay particular attention to the verb. The moment they hear it, they look up the entry for this verb in a mental dictionary. The dictionary will contain a list of the possible constructions associated with that verb. For example:
| KICK | + NP | HE KICKED THE BALL |
| EXPECT | + NP | HE EXPECTED A LETTER |
| | + TO | HE EXPECTED TO ARRIVE AT SIX O’CLOCK |
| | + THAT | HE EXPECTED THAT HE WOULD BE LATE. |