In the Beginning Was Information (24 page)
Read In the Beginning Was Information Online
Authors: Werner Gitt
Tags: #RELIGION / Religion & Science, #SCIENCE / Study & Teaching

a) Information content of each symbol: H
is the average information content
I
ave
(
x
) of a symbol
x
i
in a long sequence of
n
symbols.
H
thus is a characteristic of a language when
n
is large enough. Because of the different letter frequencies in various languages,
H
has a specific value for every language (e.g.,
H
1
= 4.045 77 for English and for German it is 4.112 95).
b) Expectation value of the information content of a symbol: H
can also be regarded as the expectation value of the information content of a symbol arriving from a continuously transmitting source.
c) The mean decision content per symbol: H
can also be regarded as the mean decision content of a symbol. It is always possible to encode the symbols transmitted by a source of messages into a sequence of binary symbols (0 and 1). If we regard the binary code of one symbol as a binary word, then
H
can also be interpreted as follows (note that binary words do not necessarily have the same length): It is the average word length of the code required for the source of the messages. If, for instance, we want to encode the four letters of the genetic code for a computer investigation and the storage requirements have to be minimized, then H will be lb 4 = 2 binary positions (e.g., 00 = A, 01 = C, 10 = G, and 11 = T).
d) The exceptional case of symbols having equal probabilities:
This is an important case, namely that all
N
symbols of the alphabet or some other set of elements occur with the same probability
p
(
x
i
) = 1/
N
. To find the mean information content of a single symbol, we have to divide the right side of equation (8) by
n
:
(10)
H
≡
I
ave
(
x
) ≡
i
= lb
N
We now formulate this statement as a special theorem:
Theorem A1:
In the case of symbol sequences of equal probability (e.g., the digits generated by a random number generator) the average information content of a symbol is equal to the information content of each and every individual symbol.
A1.2 Mathematical Description of Statistical Information
A1.2.1 The Bit: Statistical Unit of Information
One of the chief concerns in science and technology is to express results as far as possible in a numerical form or in a formula. Quantitative measures play an important part in these endeavors. They comprise two parts: the relevant number or magnitude, and the unit of measure. The latter is a predetermined unit of comparison (e.g., meter, second, watt) which can be used to express other similarly measurable quantities.
The
bit
(abbreviated from
binary digit
) is the unit for measuring information content. The number of bits is the same as the number of binary symbols. In data processing systems, information is represented and processed in the form of electrical, optical, or mechanical signals. For this purpose, it is technically extremely advantageous, and therefore customary, to employ only two defined (binary) states and signals. Binary states have the property that only one of the two binary symbols can be involved at a certain moment. One state is designated as binary one (1), and the other as binary nought (0). It is also possible to have different pairs of binary symbols like 0 and L, YES and NO, TRUE and FALSE, and 12 V and 2 V. In computer technology, a bit also refers to the binary position in a machine word. The bit is also the smallest unit of information that can be represented in a digital computer. When text is entered in a computer, it is transformed into a predetermined binary code and also stored in this form. One letter usually requires 8 binary storage positions, known as a byte. The information content (= storage requirement) of a text is then described in terms of the number of bits required. Different pieces of text are thus accorded the same information content, regardless of sense and meaning. The number of bits only measures the statistical quantity of the information, with no regard to meaningfulness.
Two computer examples will now illustrate the advantages (e.g., to help determine the amount of storage space) and the disadvantages (e.g., ignoring the semantic aspects) of Shannon’s definition of information:
Example 1:
Storage of biological information: The human DNA molecule (body cell) is about 79 inches (2 m) long when fully stretched and it contains approximately 6 x 10
9
nucleotides (the chemical letters: adenin, cytosin, guanin, and thymin). How much statistical information is this according to Shannon’s defintion? The N = 4 chemical letters, A, C, G, and T occur nearly equally frequently; their mean information content is
H
= lb 4 = (log 4)/(log 2) = 2 bits. The entire DNA thus has an information content of I
tot
= 6 x 10
9
nucleotides x 2 bits/nucleotide = 1.2 x 10
10
bits according to equation (10). This is equal to the information contained in 750,000 typed A4 pages each containing 2,000 characters.
Example 2:
The statistical information content of the Bible: The King James Version of the English Bible consists of 3,566,480 letters and 783,137 words [D1]. When the spaces between words are also counted, then
n
= 3,566,480 + 783,137 - 1 = 4,349,616 symbols. The average information content of a single letter (also known as entropy) thus amounts to
H
= 4.046 bits (see Table 1). The total information content of the Bible is then given by
I
tot
= 4,349,616 x 4.046 = 17.6 million bits. Since the German Bible contains more letters than the English one, its information content is then larger in terms of Shannon’s theory, although the actual contents are the same as regards their meaning. This difference is carried to extremes when we consider the Shipipo language of Peru which is made up of 147 letters (see Figure 32 and Table 2). The Shipipo Bible then contains about 5.2 (= 994/191) times as much information as the English Bible. It is clear that Shannon’s definition of information is inadequate and problematic. Even when the meaning of the contents is exactly the same (as in the case of the Bible), Shannon’s theory results in appreciable differences. Its inadequacy resides in the fact that the quantity of information only depends on the number of letters, apart from the language-specific factor
H
in equation (6). If meaning is considered, the unit of information should result in equal numbers in the above case, independent of the language.
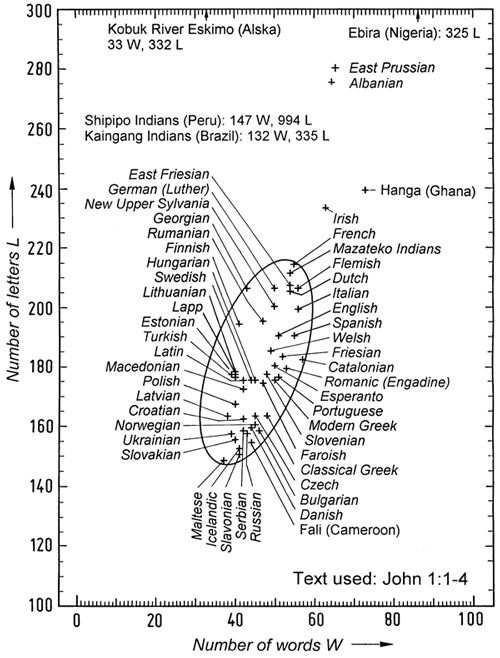 |
Figure 32: |
 |
Table 2: |
The first four verses of the Gospel of John is rendered in three African and four American languages in Table 2. In my book
So steht’s geschrieben
[
It Is Written
, G12, p. 95–98] the same verses are given in 47 different European languages for purposes of comparison. The annotation "86 W, 325 L" means that 86 words and 325 letters are used. The seventh language in Table 2 (Mazateco) is a tonal language. The various values of B and L for John 1:1–4 are plotted for 54 languages in Figure 32. These 54 languages include 47 European languages (italics) and seven African and American languages. It is remarkable that the coordinates of nearly all European languages fall inside the given ellipse. Of these, the Maltese language uses the least number of words and letters, while the Shipipo Indians use the largest number of letters for expressing the same information.
The storage requirements of a sequence of symbols should be distinguished from its information content as defined by Shannon. Storage space is not concerned with the probability of the appearance of a symbol, but only with the total number of characters. In general, 8 bits (= 1 byte) are required for representing one symbol in a data processing system. It follows that the 4,349,616 letters and spaces (excluding punctuation marks) of the English Bible require eight times as many bits, namely 34.8 million.
A1.2.2 The Information Spiral
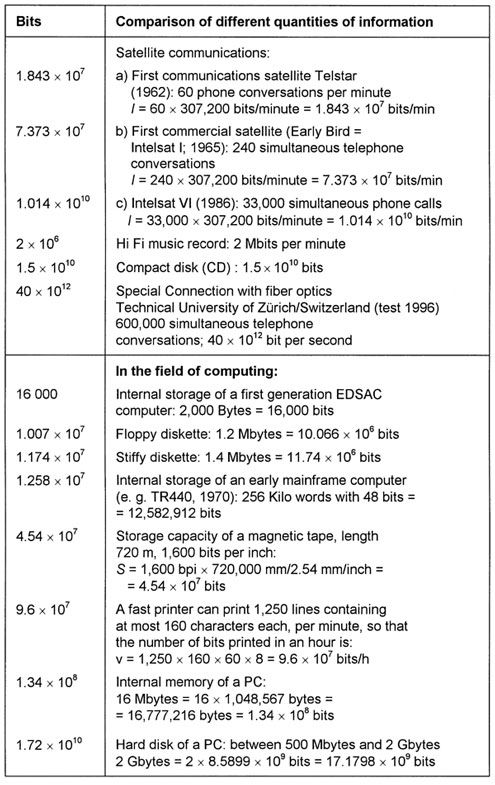
The quantities of information of a large number of examples from languages, everyday events, electronic data processing, and biological life, are given in Table 3 in terms of bits. A graphical representation of the full range of values requires more than 24 orders of magnitude (powers of ten), so that a logarithmic spiral has been chosen here. A selection of values from Table 3 is represented in Figure 33 (page 191) where each scale division indicates a tenfold increase from the previous one.
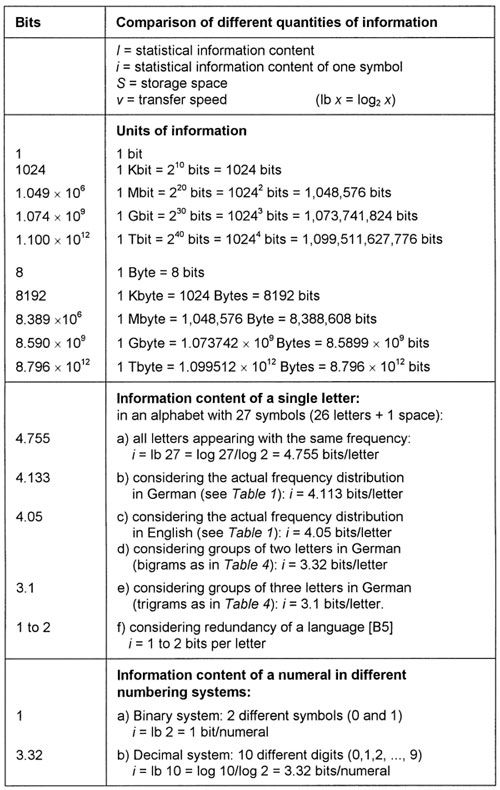 |
Table 3: |
 |
 |